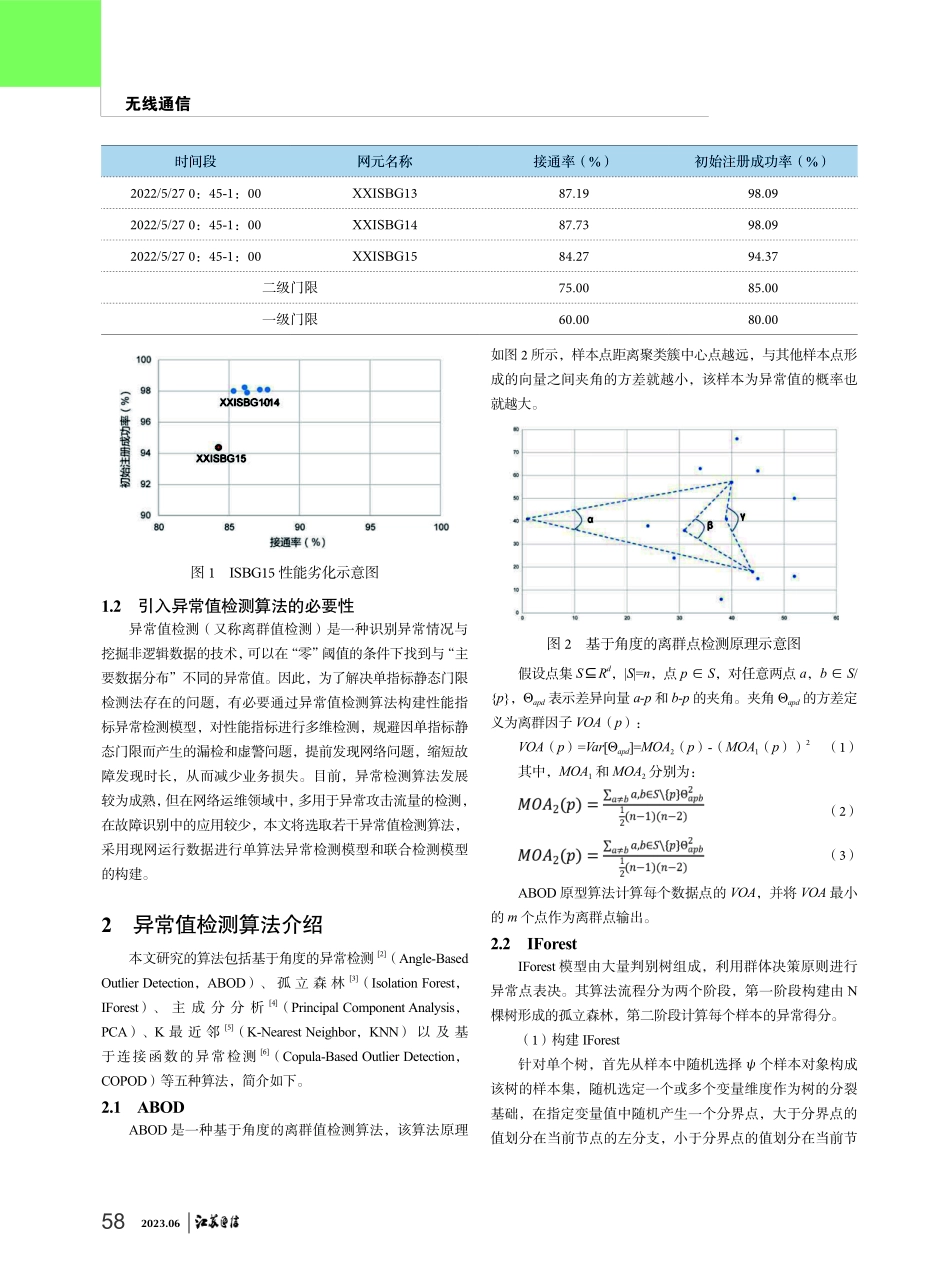
572023.06无线通信0引言面对“网、云、数、智、边、端、链”不断深度融合、新的业务形态不断发展对网络运维提出的新挑战,中国移动提出“零等待、零故障、零接触”“自配置、自修复、自优化”的自智网络[1]。自智网络对故障管理能力提出了更高的要求,而故障识别作为故障管理的起点,是监控排障领域最重要的能力之一。除了设备自身故障告警以外,性能指标也是表征设备、业务受损情况的重要数据,关键性能指标的波动性会导致网络与业务质量潜在的不稳定,甚至会引发用户直接投诉或潜在贬损。因此对性能劣化的准确识别可以及时地发现网络中的异常情况,尤其在无设备原始告警表征的情况下,性能告警是故障识别最为有效的补充手段。1网络性能劣化识别现状1.1单指标静态门限识别方法的局限性随着集中监控改革不断深化,中国移动已建立起较为成熟的性能监控体系,已将面向网络的137项指标和面向业务的194项指标进行标准化定义、分级和监测,仅江苏一省,性能劣化的月均派单量已接近4000张。然而,当前性能劣化类故障的识别方法仍然是依靠专家经验为单个指标设定静态门限,通过判断该指标是否触及静态门限进行识别,这种方法的局限性在于静态的门限值无法随着网络状态和业务量变化而动态更新,导致性能劣化类故障识别不够精确,例如,2022年5月27日凌晨,ISBG15进行应急倒换演练,在0:30-0:45时段,其接通率和初始注册成功率相较于同pool的其他网元因倒换操作存在轻度劣化,性能指标见表1。虽然如图1所示,XXISBG15已有明显离群特征,但由于没有达到设定门限,并未触发告警。如果网元处于非工程状态,此类性能劣化故障就极易被忽略。异常值检测算法在网络性能劣化识别中的研究与应用尤龙纪应天李岩中国移动通信集团江苏有限公司摘要:随着网络规模的不断扩大,业务形态的复杂度不断增加,单点故障极易造成较大业务影响,因此在设备告警之外,运营商必须具备网络性能劣化的提前感知手段,力求先于投诉发现问题,保障客户感知。但目前性能劣化识别主要依赖单指标静态阈值判断,这种方法无法根据网络状态动态调整阈值,导致网络性能劣化识别率不高。针对此问题,本文基于PyOD算法库完成多个AI异常检测模型的参数调优,对多维指标进行联合检测。较之单指标静态阈值的识别方法,本文提出的异常检测模型对性能劣化更为敏感,即使单个指标未达到告警阈值,仍然能够通过多维指标的细微变化识别异常,有效提升了性能劣化故障识别的准确率。关键词:自智网络;网络...