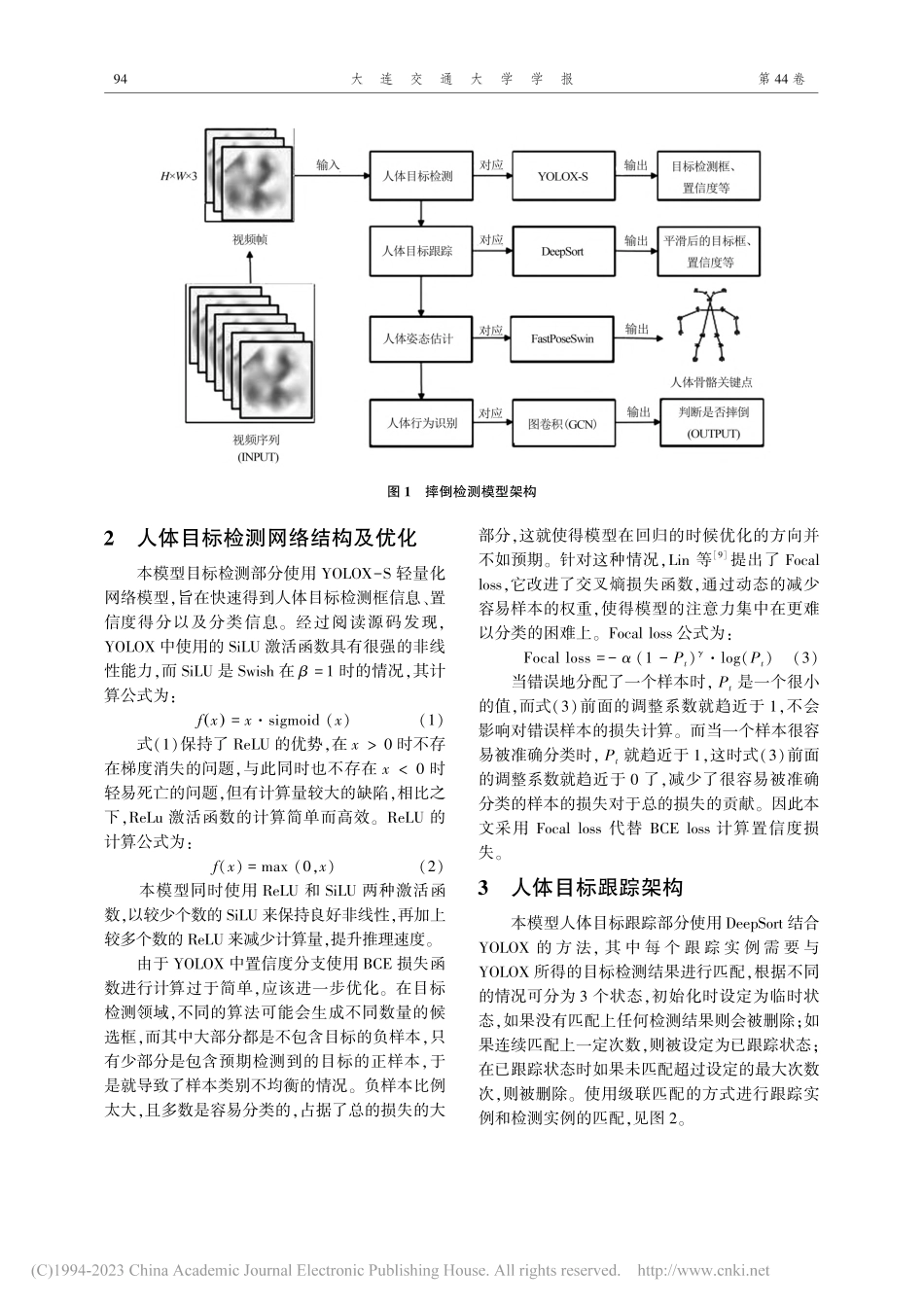
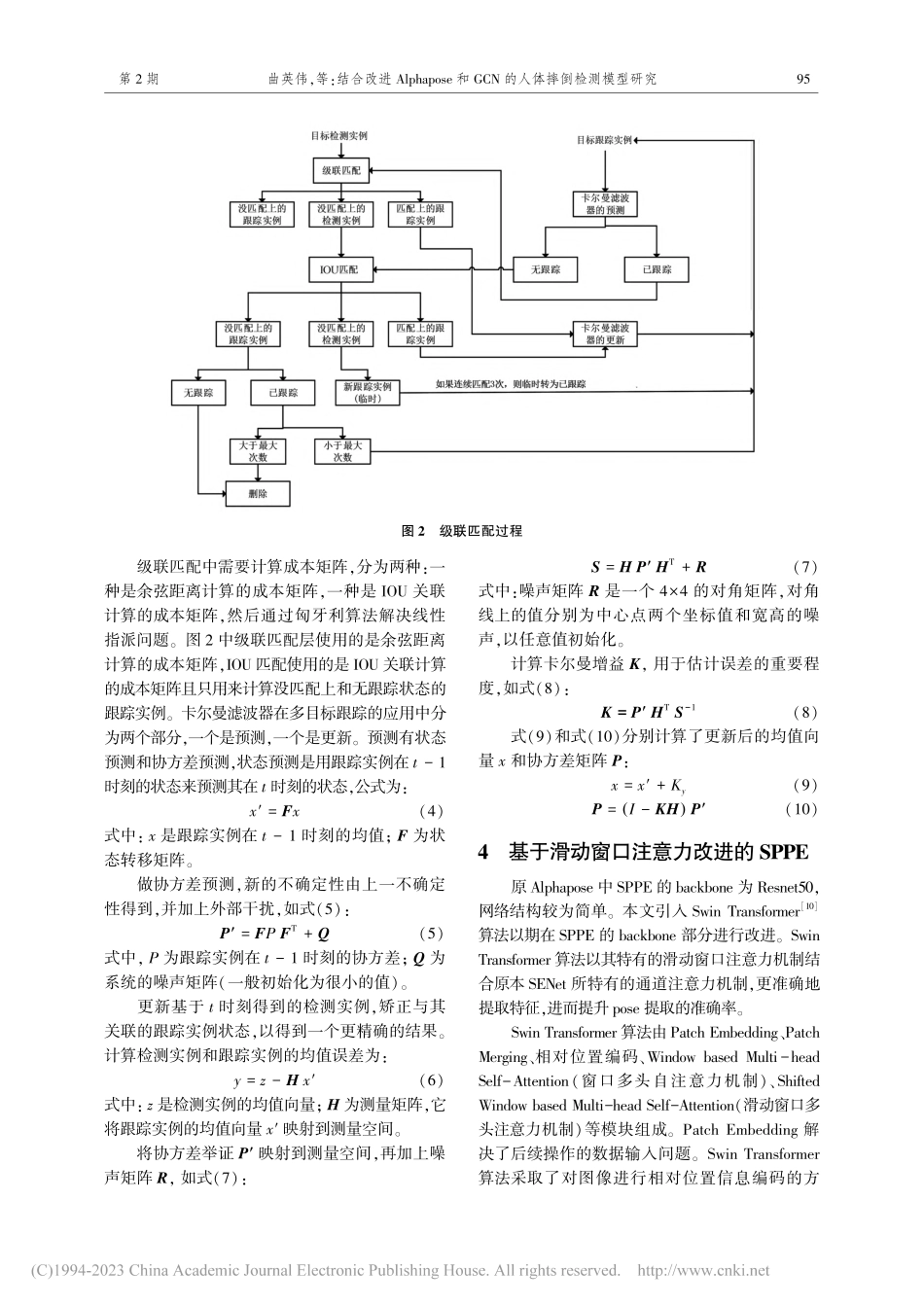
第44卷第2期2023年4月大连交通大学学报JOURNALOFDALIANJIAOTONGUNIVERSITYVol.44No.2Apr.2023■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■文章编号:1673-9590(2023)02-0093-08结合改进Alphapose和GCN的人体摔倒检测模型研究曲英伟,梁炜(大连交通大学软件学院,辽宁大连116028)摘要:为改进当前人体摔倒检测方法场景适应能力弱、易误检等不足,提出了一种基于人体骨骼关键点和GCN结合的人体摔倒检测模型。在CrownHuman、COCO2017、Le2i等数据集上进行对比试验,试验结果表明优化后的YOLOX人体目标检测算法的平均准确率达到了50.66%,较YOLOv3、YOLOv5提高了9.83%和3.97%。人体姿态估计算法的平均准确率达到了71.6%,优于OpenPose、Mask-RCNN等方法。基于图卷积的人体摔倒检测算法准确率达到92.2%,高于YOLOv5-S+pose等方法。一系列的试验结果表明,所提出的摔倒检测方法具有较高的检测精度。关键词:人体摔倒检测;YOLOX;Alphapose;人体骨骼关键点;GCN文献标识码:ADOI:10.13291/j.cnki.djdxac.2023.02.017已有的基于计算机视觉的摔倒检测模型主要有基于传统机器视觉方法和基于深度学习方法两类。基于传统机器视觉方法提取特征易受场景、光线等因素影响,准确率较低;由于硬件突破带来的算力大幅提升,基于深度学习的方法得到高速发展。郭欣等[1]搭建了使用注意力机制轻量化结构的深度卷积网络,并提取了骨骼关键点信息,检测摔倒行为依据视频帧间骨骼关键点的变化来判断。曹建荣等[2]先使用YOLOv3检测得到人体目标区域矩形框,将跌倒过程中的人体运动特征与卷积提取的特征融合,再进行摔倒判别,该方法比传统方法有更强的环境适应性。卫少洁等[3]提出一种结合Alphapose和LSTM的人体摔倒模型,主要思想是将姿态估计提取出来的人体骨骼关键点的坐标集分为x坐标集和y坐标集,将这两个坐标集分别输入长、短期记忆网络来提取时序特征,最后用一个全连接层进行分类,判断人体是否发生摔倒,但受制于LSTM需要存储的特性,不能进行实时检测。Chen等[4]提出了一种基于对称性原理...