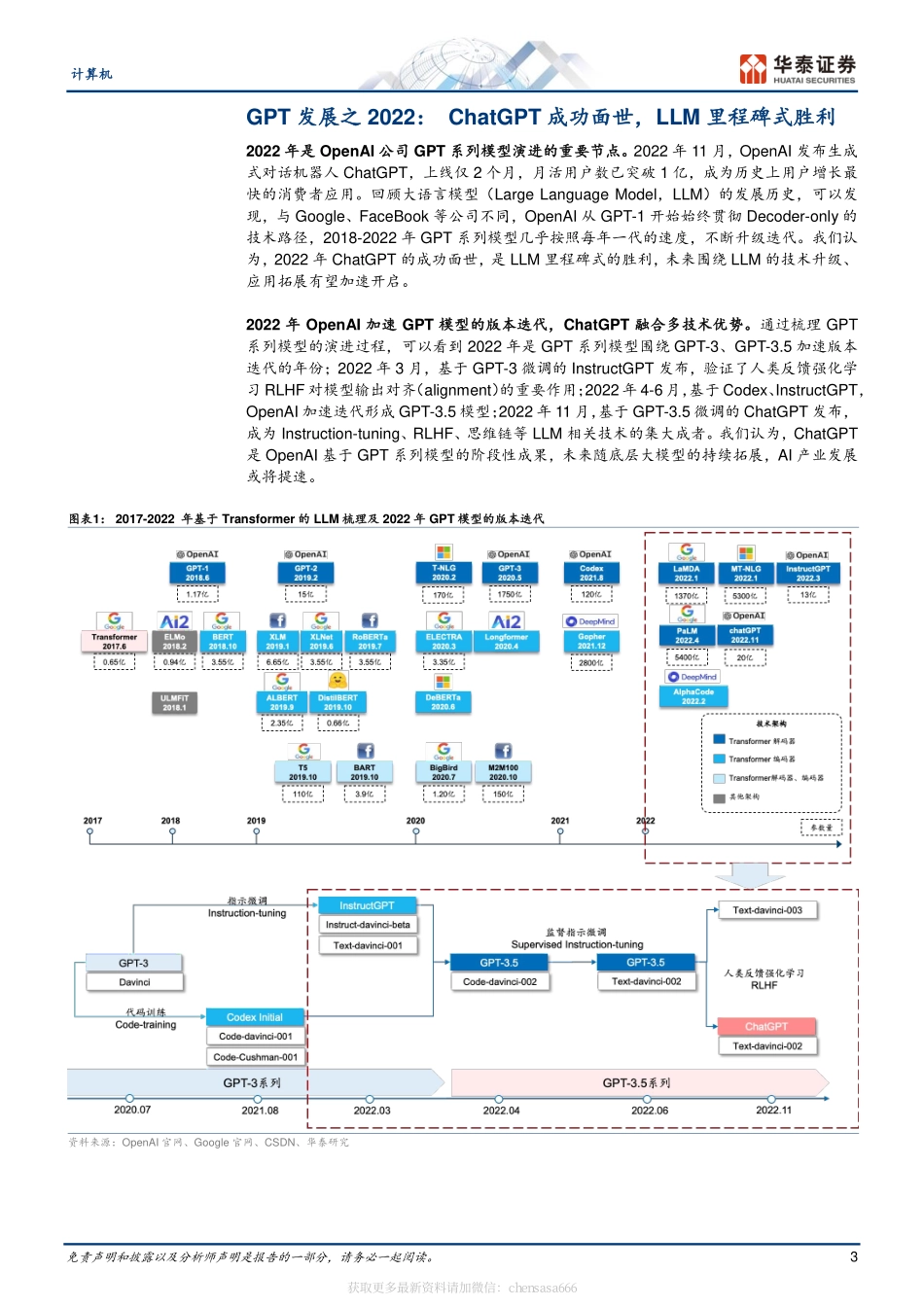
免责声明和披露以及分析师声明是报告的一部分,请务必一起阅读。1证券研究报告计算机GPT产业复盘(2022):推出ChatGPT华泰研究计算机增持(维持)研究员谢春生SACNo.S0570519080006SFCNo.BQZ938xiechunsheng@htsc.com+(86)2129872036联系人袁泽世,PhDSACNo.S0570122080053yuanzeshi@htsc.com+(86)2128972228行业走势图资料来源:Wind,华泰研究2023年2月19日│中国内地专题研究溯源GPT发展:2022年ChatGPT面世,LLM里程碑式胜利梳理GPT系列模型的演进过程,可以看到2022年是GPT系列模型围绕GPT-3、GPT-3.5加速版本迭代的重要节点,2022年11月,ChatGPT成功面世,成为历史上用户增长最快的消费者应用。与Google、FaceBook等公司不同,OpenAI从初代模型GPT-1开始,始终贯彻只有解码器(Decoder-only)的技术路径,2018-2022年GPT系列模型几乎按照每年一代的速度,不断迭代升级。我们认为,2022年ChatGPT的成功,是OpenAI公司GPT系列模型的阶段性胜利,也是大语言模型LLM的里程碑式胜利,后续围绕LLM的技术升级、应用拓展有望加速开启,AI产业发展或将提速。ChatGPT:引入人类反馈,模型训练SFT、RM、PPO三步走ChatGPT、InstructGPT分别是基于GPT-3.5、GPT-3微调得到的新版本模型,其核心目标是实现模型输出与人类预期的需求对齐(alignment),人类反馈强化学习RLHF成为模型需求对齐的重要技术支持。ChatGPT、InstructGPT的模型训练主要包括三步:1)有监督微调SFT:通过指示学习对模型进行有监督微调;2)奖励模型RM训练:借助人工标注员对模型输出进行排序,反馈训练得到奖励模型,此步是人类反馈的重要体现;3)近段策略优化PPO强化学习:通过监督学习策略生成PPO模型,优化、迭代原有模型参数。总结来看,RLHF让模型输出更加符合用户预期。ChatGPTVSInstructGPT:核心是基础大模型的不同对比ChatGPT与InstructGPT的训练方法,可以发现,两者的训练方法基本一致,核心区别在于InstructGPT、ChatGPT分别基于GPT-3、GPT-3.5进行模型微调。与GPT-3相比,GPT-3.5增加了代码训练与指示微调:1)代码训练(Code-training):让GPT-3.5模型具备更好的代码生成与代码理解能力,同时间接拥有了复杂推理能力;2)指示微调(Instruction-tuning):让GPT-3.5模型具备更好的泛化能力,同时模型的生成结果更加符合人类的预期。作为基于GPT-3.5的模型微调产物,ChatGPT具备更好的问答能力,更加遵循人类的价值观。OpenAIVSGoogle:OpenAI贯彻Decoder-only路径,...