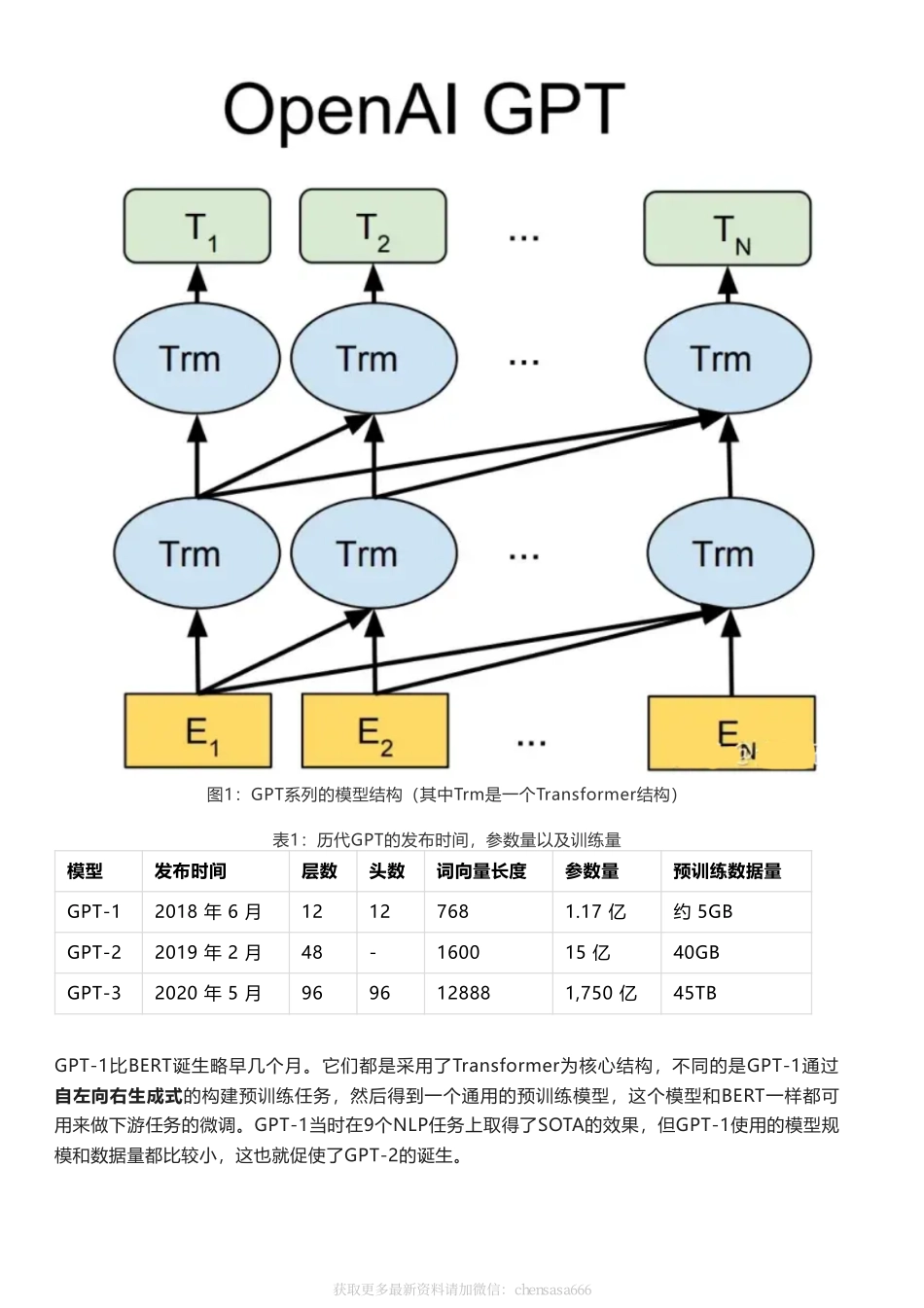
ChatGPT专题|ChatGPT/InstructGPT详解获取更多最新资料请加微信:chensasa666前言GPT系列是OpenAI的一系列预训练文章,GPT的全称是GenerativePre-TrainedTransformer,顾名思义,GPT的目的就是通过Transformer为基础模型,使用预训练技术得到通用的文本模型。目前已经公布论文的有文本预训练GPT-1,GPT-2,GPT-3,以及图像预训练iGPT。据传还未发布的GPT-4是一个多模态模型。最近非常火的ChatGPT和今年年初公布的[1]是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(InstructionLearning)和人工反馈的强化学习(ReinforcementLearningfromHumanFeedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。所以要搞懂ChatGPT,我们必须要先读懂InstructGPT。1.背景知识在介绍ChatGPT/InstructGPT之前,我们先介绍它们依赖的基础算法。1.1GPT系列基于文本预训练的GPT-1[2],GPT-2[3],GPT-3[4]三代模型都是采用的以Transformer为核心结构的模型(图1),不同的是模型的层数和词向量长度等超参,它们具体的内容如表1。获取更多最新资料请加微信:chensasa666图1:GPT系列的模型结构(其中Trm是一个Transformer结构)表1:历代GPT的发布时间,参数量以及训练量模型发布时间层数头数词向量长度参数量预训练数据量GPT-12018年6月12127681.17亿约5GBGPT-22019年2月48-160015亿40GBGPT-32020年5月9696128881,750亿45TBGPT-1比BERT诞生略早几个月。它们都是采用了Transformer为核心结构,不同的是GPT-1通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果,但GPT-1使用的模型规模和数据量都比较小,这也就促使了GPT-2的诞生。获取更多最新资料请加微信:chensasa666对比GPT-1,GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据(表1)。GPT-2最重要的思想是提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,这个思想也是提示学习(PromptLearning)的前身。GPT-2在诞生之初也引发了不少的轰动,它生成的新闻足以欺骗大多数人类,达到以假乱真的效果。甚至当时被称为“AI界最危险的武器”,很多门户网站也命令禁止使用GPT-2生成的新闻。GPT-3被提出时,除了它远超GPT-2的效果外,引起更...