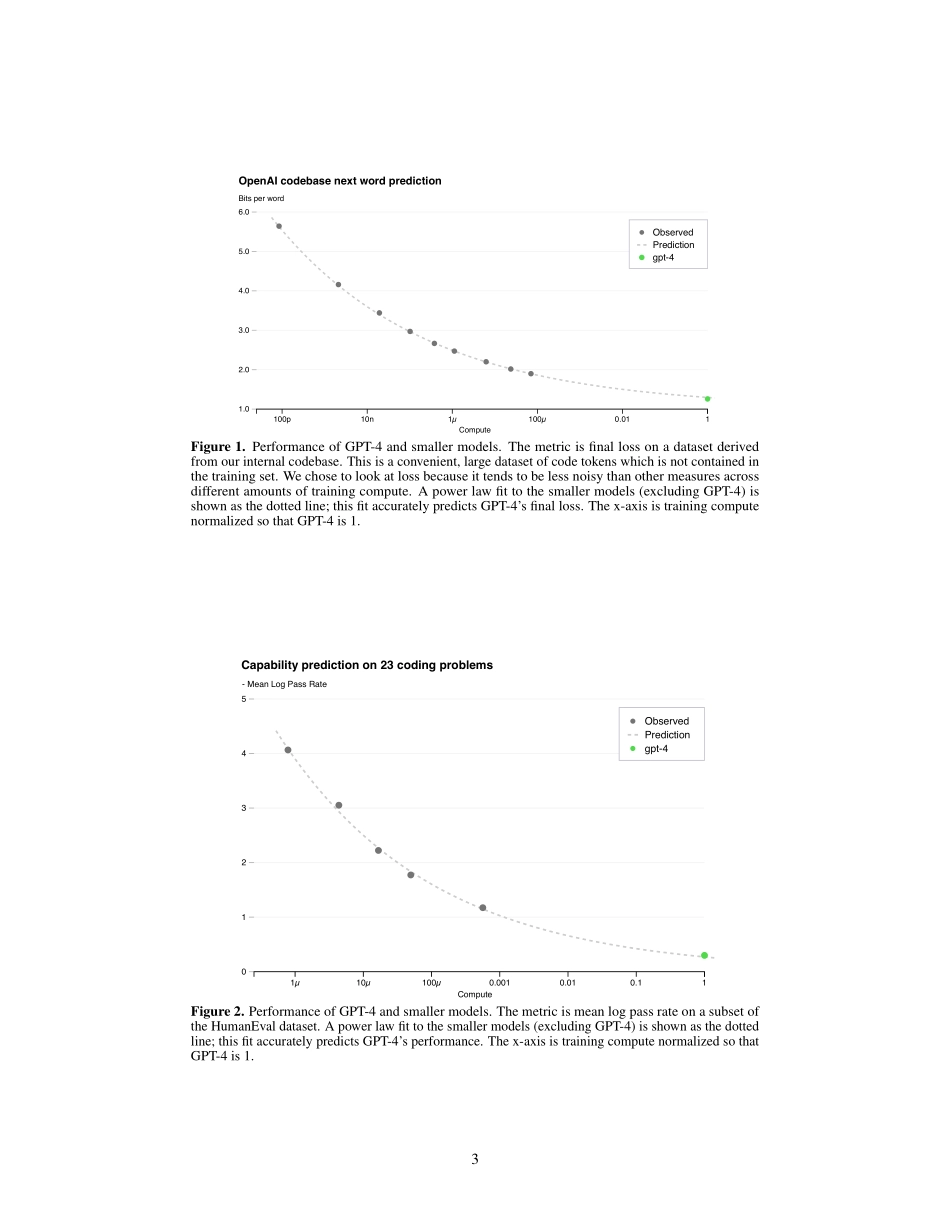
GPT-4TechnicalReportOpenAI∗AbstractWereportthedevelopmentofGPT-4,alarge-scale,multimodalmodelwhichcanacceptimageandtextinputsandproducetextoutputs.Whilelesscapablethanhumansinmanyreal-worldscenarios,GPT-4exhibitshuman-levelperformanceonvariousprofessionalandacademicbenchmarks,includingpassingasimulatedbarexamwithascorearoundthetop10%oftesttakers.GPT-4isaTransformer-basedmodelpre-trainedtopredictthenexttokeninadocument.Thepost-trainingalignmentprocessresultsinimprovedperformanceonmeasuresoffactualityandadherencetodesiredbehavior.Acorecomponentofthisprojectwasdevelopinginfrastructureandoptimizationmethodsthatbehavepredictablyacrossawiderangeofscales.ThisallowedustoaccuratelypredictsomeaspectsofGPT-4’sperformancebasedonmodelstrainedwithnomorethan1/1,000ththecomputeofGPT-4.1IntroductionThistechnicalreportpresentsGPT-4,alargemultimodalmodelcapableofprocessingimageandtextinputsandproducingtextoutputs.Suchmodelsareanimportantareaofstudyastheyhavethepotentialtobeusedinawiderangeofapplications,suchasdialoguesystems,textsummarization,andmachinetranslation.Assuch,theyhavebeenthesubjectofsubstantialinterestandprogressinrecentyears[1–28].Oneofthemaingoalsofdevelopingsuchmodelsistoimprovetheirabilitytounderstandandgeneratenaturallanguagetext,particularlyinmorecomplexandnuancedscenarios.Totestitscapabilitiesinsuchscenarios,GPT-4wasevaluatedonavarietyofexamsoriginallydesignedforhumans.Intheseevaluationsitperformsquitewellandoftenoutscoresthevastmajorityofhumantesttakers.Forexample,onasimulatedbarexam,GPT-4achievesascorethatfallsinthetop10%oftesttakers.ThiscontrastswithGPT-3.5,whichscoresinthebottom10%.OnasuiteoftraditionalNLPbenchmarks,GPT-4outperformsbothpreviouslargelanguagemodelsandmoststate-of-the-artsystems(whichoftenhavebenchmark-specifictrainingorhand-engineering).OntheMMLUbenchmark[29,30],anEnglish-languagesuiteofmultiple-choicequestionscovering57subjects,GPT-4notonlyoutperformsexistingmodelsbyaconsiderablemargininEnglish,butalsodemonstratesstrongperformanceinotherlan...