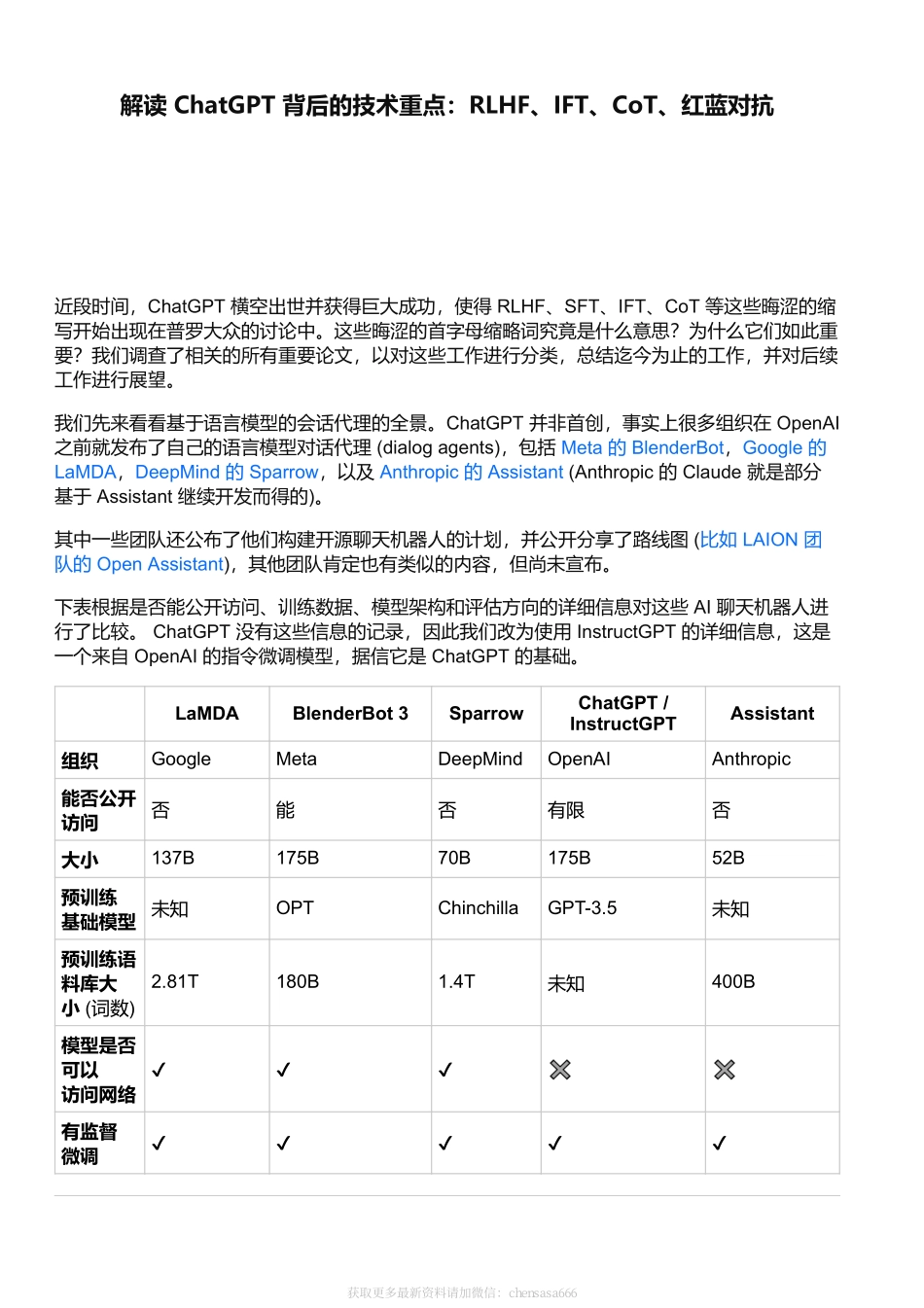
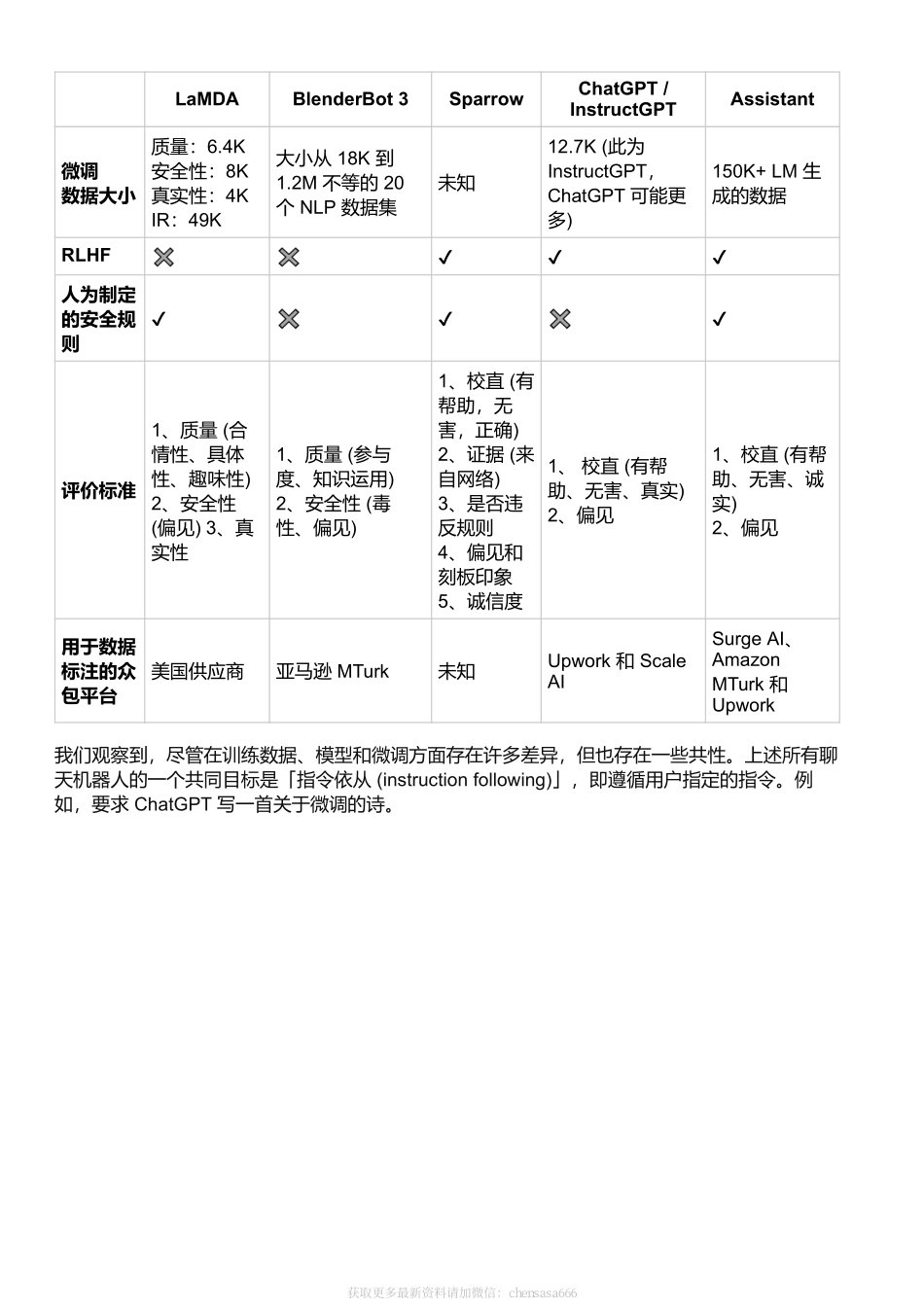
解读ChatGPT背后的技术重点:RLHF、IFT、CoT、红蓝对抗近段时间,ChatGPT横空出世并获得巨大成功,使得RLHF、SFT、IFT、CoT等这些晦涩的缩写开始出现在普罗大众的讨论中。这些晦涩的首字母缩略词究竟是什么意思?为什么它们如此重要?我们调查了相关的所有重要论文,以对这些工作进行分类,总结迄今为止的工作,并对后续工作进行展望。我们先来看看基于语言模型的会话代理的全景。ChatGPT并非首创,事实上很多组织在OpenAI之前就发布了自己的语言模型对话代理(dialogagents),包括Meta的BlenderBot,Google的LaMDA,DeepMind的Sparrow,以及Anthropic的Assistant(Anthropic的Claude就是部分基于Assistant继续开发而得的)。其中一些团队还公布了他们构建开源聊天机器人的计划,并公开分享了路线图(比如LAION团队的OpenAssistant),其他团队肯定也有类似的内容,但尚未宣布。下表根据是否能公开访问、训练数据、模型架构和评估方向的详细信息对这些AI聊天机器人进行了比较。ChatGPT没有这些信息的记录,因此我们改为使用InstructGPT的详细信息,这是一个来自OpenAI的指令微调模型,据信它是ChatGPT的基础。LaMDABlenderBot3SparrowChatGPT/InstructGPTAssistant组织GoogleMetaDeepMindOpenAIAnthropic能否公开访问否能否有限否大小137B175B70B175B52B预训练基础模型未知OPTChinchillaGPT-3.5未知预训练语料库大小(词数)2.81T180B1.4T未知400B模型是否可以访问网络✔✔✔✖✖有监督微调✔✔✔✔✔获取更多最新资料请加微信:chensasa666LaMDABlenderBot3SparrowChatGPT/InstructGPTAssistant微调数据大小质量:6.4K安全性:8K真实性:4KIR:49K大小从18K到1.2M不等的20个NLP数据集未知12.7K(此为InstructGPT,ChatGPT可能更多)150K+LM生成的数据RLHF✖✖✔✔✔人为制定的安全规则✔✖✔✖✔评价标准1、质量(合情性、具体性、趣味性)2、安全性(偏见)3、真实性1、质量(参与度、知识运用)2、安全性(毒性、偏见)1、校直(有帮助,无害,正确)2、证据(来自网络)3、是否违反规则4、偏见和刻板印象5、诚信度1、校直(有帮助、无害、真实)2、偏见1、校直(有帮助、无害、诚实)2、偏见用于数据标注的众包平台美国供应商亚马逊MTurk未知Upwork和ScaleAISurgeAI、AmazonMTurk和Upwork我们观察到,尽管在训练数据、模型和微调方面存在许多差异,但也存在一些共性。上述所有聊天机器人的一个共同目标是「指令依从(instructionfollowing)」,即遵循用户指定的指令。例如...