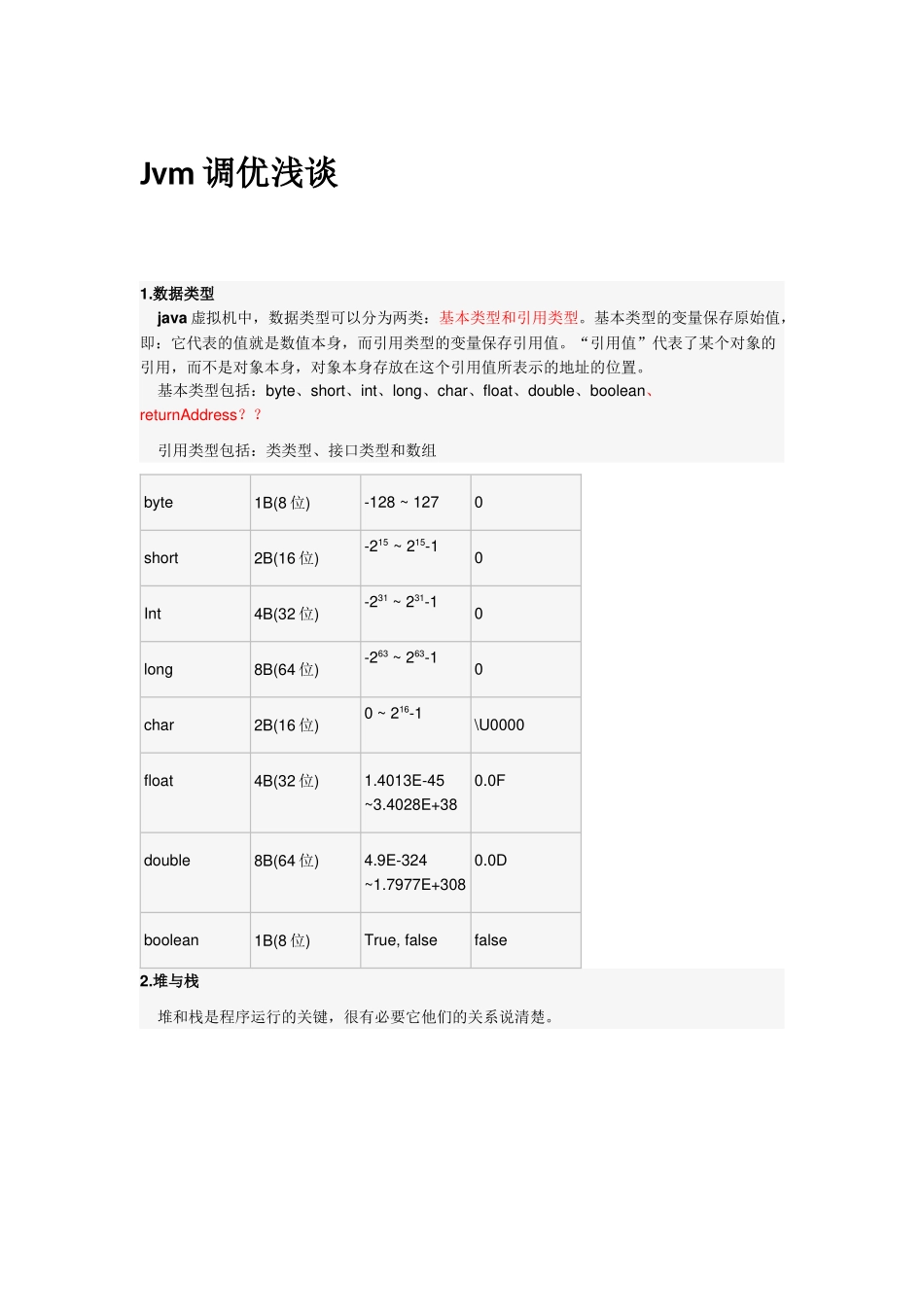
Jvm调优浅谈1.数据类型java虚拟机中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:它代表的值就是数值本身,而引用类型的变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。基本类型包括:byte、short、int、long、char、float、double、boolean、returnAddress??引用类型包括:类类型、接口类型和数组byte1B(8位)-128~1270short2B(16位)-215~215-10Int4B(32位)-231~231-10long8B(64位)-263~263-10char2B(16位)0~216-1\U0000float4B(32位)1.4013E-45~3.4028E+380.0Fdouble8B(64位)4.9E-324~1.7977E+3080.0Dboolean1B(8位)True,falsefalse2.堆与栈堆和栈是程序运行的关键,很有必要它他们的关系说清楚。栈是运行时的单位,而堆是存储的单元。栈解决程序的运行问题,即程序如何执行,或者说如何处理数据,堆解决的是数据存储的问题,即数据怎么放,放在哪儿。在java中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。而堆则是所有线程共享的。栈因为是运行单位,因此里面存储的信息都是跟当前线程(或程序)相关的信息。包括局部变量、程序运行状态、方法返回值等等,而堆只负责存储对象信息。为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗?1.从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。2.堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。3.栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力,而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。4.面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在...